Resources
 |
PAB Dataset [website] We propose a new task, text-based person anomaly search, locating pedestrians engaged in both routine or anomalous activities via text. To enable the training and evaluation of this new task, we construct a large-scale image-text Pedestrian Anomaly Behavior (PAB) benchmark, featuring a broad spectrum of actions, e.g., running, performing, playing soccer, and the corresponding anomalies, e.g., lying, being hit, and falling of the same identity. The training set of PAB comprises 1,013,605 synthesized image-text pairs of both normalities and anomalies, while the test set includes 1,978 real-world image-text pairs. |
 |
MALS Dataset [website] We present a large Multi-Attribute and Language Search dataset for text-based person retrieval, called MALS, and explore the feasibility of performing pre-training on both attribute recognition and image-text matching tasks in one stone. In particular, MALS contains 1, 510, 330 image-text pairs, which is about 37.5× larger than prevailing CUHK-PEDES, and all images are annotated with 27 attributes. |
 |
University-1652 Dataset [website] [SoTA] We collect 1652 buildings of 72 universities around the world. University-1652 contains data from three platforms, i.e., synthetic drones, satellites and ground cameras of 1,652 university buildings around the world. To our knowledge, University-1652 is the first drone-based geo-localization dataset and enables two new tasks, i.e., drone-view target localization and drone navigation. |
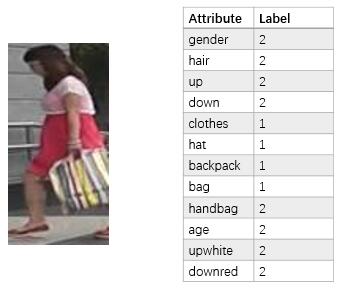 |
Market-1501 and DukeMTMC-reID Attribute Datasets [website] We manually annotate attribute labels for two large-scale re-ID datasets, and systematically investigate how person re-ID and attribute recognition benefit from each other. |
 |
3D Market-1501 Dataset [website] You could find the point-cloud format Market-1501 Dataset at https://github.com/layumi/person-reid-3d. |
 |
DG-Market Dataset We provide our generated images and make a large-scale synthetic dataset called DG-Market. This dataset is generated by our [DG-Net](https://arxiv.org/abs/1904.07223) and consists of 128,307 images (613MB), about 10 times larger than the training set of original Market-1501 (even much more can be generated with DG-Net). It can be used as a source of unlabeled training dataset for semi-supervised learning. You may download the dataset from [Google Drive] (or [Baidu Disk]) password: qxyh). |
- HQ-Market Super-resolution Dataset. [website]
- DukeMTMC-reID Dataset. [website] [SoTA]
- DukeMTMC-Pose Dataset. [website]
- UTS Person-reID Tutorial. [website]
Awesome Lists
- Awesome Segmentation Domain Adaptation
- Awesome Vehicle Retrieval
- Awesome Fools
- Awesome Geo-localization
Motivations
- The illustrated guide to a Ph.D.
- 熊辉: 为什么人前进的路总是被自己挡住
- 陈海波: 一名系统研究者的攀登之路
- 勇气与真意——关于围棋的八卦
- 山世光:致联系报考我免试研究生的同学们